
EVCache is a distributed in-memory caching solution based on memcached & spymemcached that is well integrated with Netflix OSS and AWS EC2 infrastructure. Today we are announcing the open sourcing of EVCache client library on Github.
EVCache is an abbreviation for:
Ephemeral - The data stored is for a short duration as specified by its TTL(Time To Live).
Volatile - The data can disappear any time (Evicted).
Cache – An in-memory key-value store.
The advantages of distributed caching are:
- Faster response time compared to data being fetched from source/database
- Reduces the load and number of servers needed to handle the requests as most of the requests are served by the cache
- Increases the throughput of the services fronted by the cache
Please read more about EVCache from our earlier blog post for more details.
What is an EVCache App?
EVCache App is a logical grouping of one or more memcached instances (servers). Each instance can be a
- EVCache Server (to be open sourced soon) running memcached and a Java sidecar app
- EC2 instance running memcached
- ElastiCache instance
- instance that can talk memcahced protocol (eg. Couchbase, MemcacheDB)
Each app is associated with a name. Though it is not recommended, a memcached instance can be shared across multiple EVCache Apps.
What is an EVCache Client?
EVCache client manages all the operations between an Java application and EVCache App.
What is an EVCache Server?
EVCache Server is an EC2 instance running an instances of memcached and a Java Sidecar application. The sidecar is responsible for interacting with Eureka, monitoring the memcached process and collecting and reporting performance data to the Servo. This will be Open Sourced soon.
Generic EVCache Deployment
The Figure 1 shows an EVCache App consisting of 3 memcached nodes with an EVCache client connecting to it.
Figure 1
The data is sharded across the memcached nodes based on Ketama consistent hashing algorithm. In this mode all the memcached nodes can be in the same availability zone or spread out across multiple availability zones. Multi-Cluster EVCache Deployment
The Figure 2 shows an EVCache App in 2 Clusters (A & B) with 3 memcached nodes in each Cluster. Data is replicated between the two clusters. To achieve low latency, reliability and isolation all the EC2 instances for a cluster should be in the same availability zone. This way if an availability zone is having any issues the performance of the other zone is not impacted. In a scenario where we lose instances in one cluster, we can dynamically set that cluster to “write only” and direct all the read traffic to other zone. This ensures that latency and cache hit rate is not impacted.

Figure 2
In the above scenario, the data is replicated across both the clusters and is sharded across the 3 instances in each cluster based on Ketama consistent hashing algorithm. All the reads (get, getBulk, getAndTouch) by a client are sent to the same zone whereas the writes(set & delete) are done on both the zones. The data replication across both the clusters increases its availability. Since the data is always read from the local zone this improves the latency. This approach is best suited if you want to achieve better performance with higher reliability.
If some data is lost due to an instance failure or eviction in a cluster, then the data can be fetched from the other cluster. Having fallback improves the both availability & reliability. In most cases fetching data from other cluster(fallback) is much faster than getting the data from source.
EVCache Deployment using Eureka
The Figure 3 shows an EVCache App in 3 Clusters (A, B & C) with 3 EVCache servers in each Cluster. Each cluster is in an availability zones. An EVCache server (to be open sourced soon) consists of a memcached instance and sidecar app. The sidecar app interacts with Eureka Server and monitor the memcached process.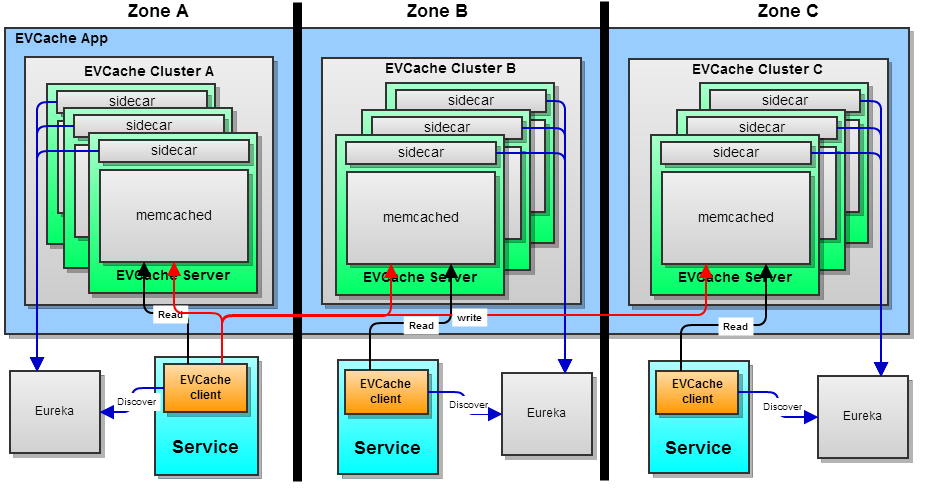
Figure 3
In the above scenario the EVCache client gets the list of servers from Eureka and creates cluster based on the availability zone of each EVCache Server. If the EVCache Server instances are added or removed the EVCache client re-configures itself to reflect this change. This is transparent to the client.
Similar to Multi-Clustered deployment the data is sharded across the 3 instances within the same zone based on Ketama consistent hashing algorithm. All the reads by a client are performed on the same zone as the client whereas the writes are done across all the zones. This ensures that data is replicated across all the zones thus increasing its availability. Since the data is always read from the local zone this improves the latency at the same time improving the data reliability.
If zone fallback is enabled and some data is lost due to instance/zone failure or eviction, then the data can be fetched from the clusters in other zone. This however causes an increase in latency but higher reliability. In most cases fetching data from other zone is much faster than getting the data from source.
Netflix OSS - All Netflix Open Source Software
EVCache - Sources & EVCache Wiki - Documentation & Configuration
memcached - A high-performance in-memory data store
spymemcached - Java Client to memcached
Archaius - Library for configuration management API
Eureka - Discovery and Managing EVCache servers
Servo - Application Monitoring Library
If you like building infrastructure components like this, for a service that millions of people use world wide, take a look at http://jobs.netflix.com.

comment 0 التعليقات:
more_vertsentiment_satisfied Emoticon