In most applications there is some amount of data that will be frequently used. Some of this data is transient and can be recalculated, while other data will need to be fetched from the database or a middle tier service. In the Netflix cloud architecture we use caching extensively to offset some of these operations. This document details Netflix’s implementation of a highly scalable memcache-based caching solution, internally referred to as EVCache.
Why do we need Caching?
Some of the objectives of the Cloud initiative were- Faster response time compared to Netflix data center based solution
- Session based App in data center to Stateless without sessions in the cloud
- Use NoSQL based persistence like Cassandra/SimpleDB/S3
To solve these we needed the ability to store data in a cache that was Fast, Shared and Scalable. We use cache to front the data that is computed or retrieved from a persistence store like Cassandra, or other Amazon AWS’ services like S3 and SimpleDB and they can take several hundred milliseconds at the 99th percentile, thus causing a widely variable user experience. By fronting this data with a cache, the access times would be much faster & linear and the load on these datastores would be greatly reduced. Caching also enables us to respond to sudden request spikes more effectively. Additionally, an overloaded service can often return a prior cached response; this ensures that user gets a personalized response instead of a generic response. By using caching effectively we have reduced the total cost of operation.
What is EVCache?
EVCache is a memcached & spymemcached based caching solution that is well integrated with Netflix and AWS EC2 infrastructure.EVCache is an abbreviation for:
Ephemeral - The data stored is for a short duration as specified by its TTL1 (Time To Live).
Volatile - The data can disappear any time (Evicted2).
Cache – An in-memory key-value store.
How is it used?
We have over 25 different use cases of EVCache within Netflix. A particular use case is a users Home Page. For Ex, to decide which Rows to show to a particular user, the algorithm needs to know the Users Taste, Movie Viewing History, Queue, Rating, etc. This data is fetched from various services in parallel and is fronted using EVCache by these services.

Client: A Java client discovers EVCache servers and manages all the CRUD3 (Create, Read, Update & Delete) operations. The client automatically handles the case when servers are added to or removed from the cluster. The client replicates data (AWS Zone5 based) during Create, Update & Delete Operations; on the other hand, for Read operations the client gets the data from the server which is in the same zone as the client.
We will be open sourcing this Java client sometime later this year so we can share more of our learnings with the developer community.

Features
We will now detail the features including both add-ons by Netflix and those that come with memcache.- Overview
- Distributed Key-Value store, i.e., the cache is spread across multiple instances
- AWS Zone-Aware and data can be replicated across zones.
- Registers and works with Netflix’s internal Naming Service for automatic discovery of new nodes/services.
- To store the data, Key has to be a non-null String and value can be a non-null byte-array, primitives, or serializable object. Value should be less than 1 MB.
- As a generic cache cluster that can be used across various applications, it supports an optional Cache Name, to be used as namespace to avoid key collisions.
- Typical cache hit rates are above 99%.
- Works well with Netflix Persister Framework7. For E.g., In-memory ->backed by EVCache -> backed by Cassandra/SimpleDB/S3
- Elasticity and deployment ease: EVCache is linearly scalable. We monitor capacity and can add capacity within a minute and potentially re-balance and warm data in the new node within a few minutes. Note that we have pretty good capacity modeling in place and so capacity change is not something we do very frequently but we have good ways of adding capacity while actively managing the cache hit rate. Stay tuned for more on this scalable cache warmer in an upcoming blog post.
- Latency: Typical response time in low milliseconds. Reads from EVCache are typically served back from within the same AWS zone. A nice side effect of zone affinity is that we don’t have any data transfer fees for reads.
- Inconsistency: This is a Best Effort Cache and the data can get inconsistent. The architecture we have chosen is speed instead of consistency and the applications that depend on EVCache are capable of handling any inconsistency. For data that is stored for a short duration, TTL ensures that the inconsistent data expires and for the data that is stored for a longer duration we have built consistency checkers that repairs it.
- Availability: Typically, the cluster never goes down as they are spread across multiple Amazon Availability Zones. When instances do go down occasionally, cache misses are minimal as we use consistent hashing to shard the data across the cluster.
- Total Cost of Operations: Beyond the very low cost of operating the EVCache cluster, one has to be aware that cache misses are generally much costlier - the cost of accessing services AWS SimpleDB, AWS S3, and (to a lesser degree) Cassandra on EC2, must be factored in as well. We are happy with the overall cost of operations of EVCache clusters which are highly stable, linearly scalable.
Under the Hood
Server: The Server consist of the following:- memcached server.
- Java Sidecar - A Java app that communicates with the Discovery Service6( Name Server) and hosts admin pages.
- Various apps that monitor the health of the services and report stats.

Client: A Java client discovers EVCache servers and manages all the CRUD3 (Create, Read, Update & Delete) operations. The client automatically handles the case when servers are added to or removed from the cluster. The client replicates data (AWS Zone5 based) during Create, Update & Delete Operations; on the other hand, for Read operations the client gets the data from the server which is in the same zone as the client.
We will be open sourcing this Java client sometime later this year so we can share more of our learnings with the developer community.
Single Zone Deployment
The figure below image illustrates the scenario in AWS US-EAST Region4 and Zone-A where an EVCache cluster with 3 instances has a Web Application performing CRUD operations (on the EVcache system).- Upon startup, an EVCache Server instance registers with the Naming Service6 (Netflix’s internal name service that contains all the hosts that we run).
- During startup of the Web App, the EVCache Client library is initialized which looks up for all the EVCache server instances registered with the Naming Services and establishes a connection with them.
- When the Web App needs to perform CRUD operation for a key the EVCache client selects the instance on which these operations can be performed. We use Consistent Hashing to shard the data across the cluster.

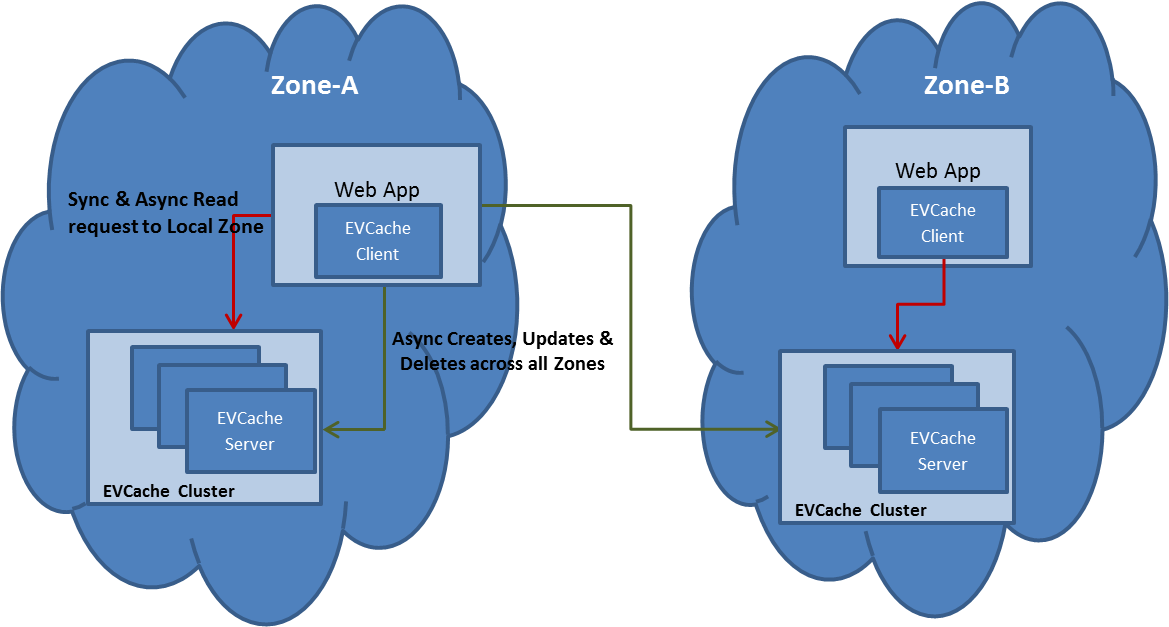
Multi-Zone Deployment
The figure below illustrates the scenario where we have replication across multiple zones in AWS US-EAST Region. It has an EVCache cluster with 3 instances and a Web App in Zone-A and Zone-B.- Upon startup, an EVCache Server instance in Zone-A registers with the Naming Service in Zone-A and Zone-B.
- During the startup of the Web App in Zone-A , The Web App initializes the EVCache Client library which looks up for all the EVCache server instances registered with the Naming Service and connects to them across all Zones.
- When the Web App in Zone-A needs to Read the data for a key, the EVCache client looks up the EVCache Server instance in Zone –A which stores this data and fetches the data from this instance.
- When the Web App in Zone-A needs to Write or Delete the data for a key, the EVCache client looks up the EVCache Server instances in Zone–A and Zone-B and writes or deletes it.
Case Study : Movie and TV show similarity
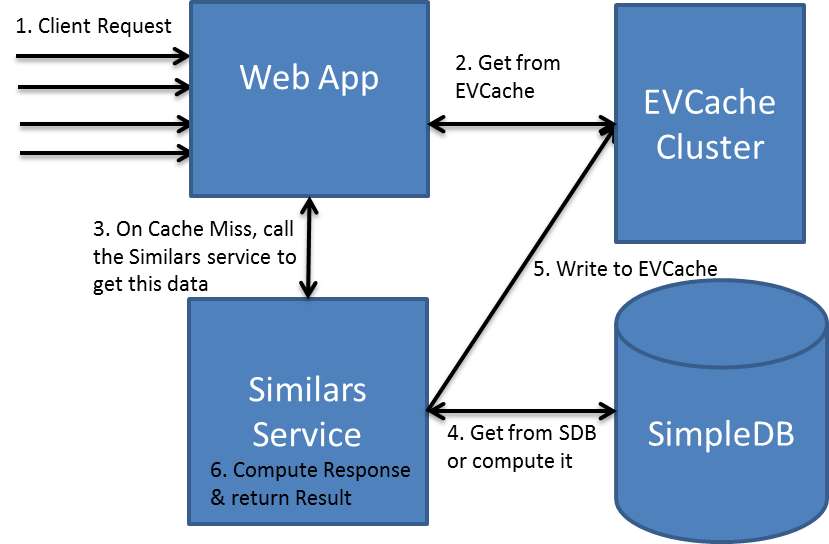
One of the applications that uses caching heavily is the Similars application. This application suggests Movies and TV Shows that have similarities to each other. Once the similarities are calculated they are persisted in SimpleDB/S3 and are fronted using EVCache. When any service, application or algorithm needs this data it is retrieved from the EVCache and result is returned.- A Client sends a request to the WebApp requesting a page and the algorithm that is processing this requests needs similars for a Movie to compute this data.
- The WebApp that needs a list of similars for a Movie or TV show looks up EVCache for this data. Typical cache hit rate is above 99.9%.
- If there is a cache miss then the WebApp calls the Similars App to compute this data.
- If the data was previously computed but missing in the cache then Similars App will read it from SimpleDB. If it were missing in SimpleDB then the app Calculates the similars for the given Movie or TV show.
- This computed data for the Movie or TV Show is then written to EVCache.
- The Similars App then computes the response needed by the client and returns it to the client.
Metrics, Monitoring, and Administration
Administration of the various clusters is centralized and all the admin & monitoring of the cluster and instances can be performed via web illustrated below.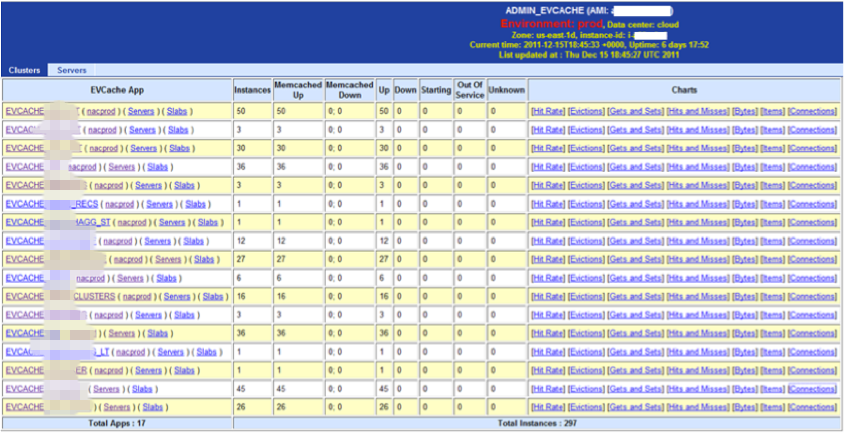
The server view below shows the details of each instance in the cluster and also rolls up by the stats for the zone. Using this tool the contents of a memcached slab can be viewed
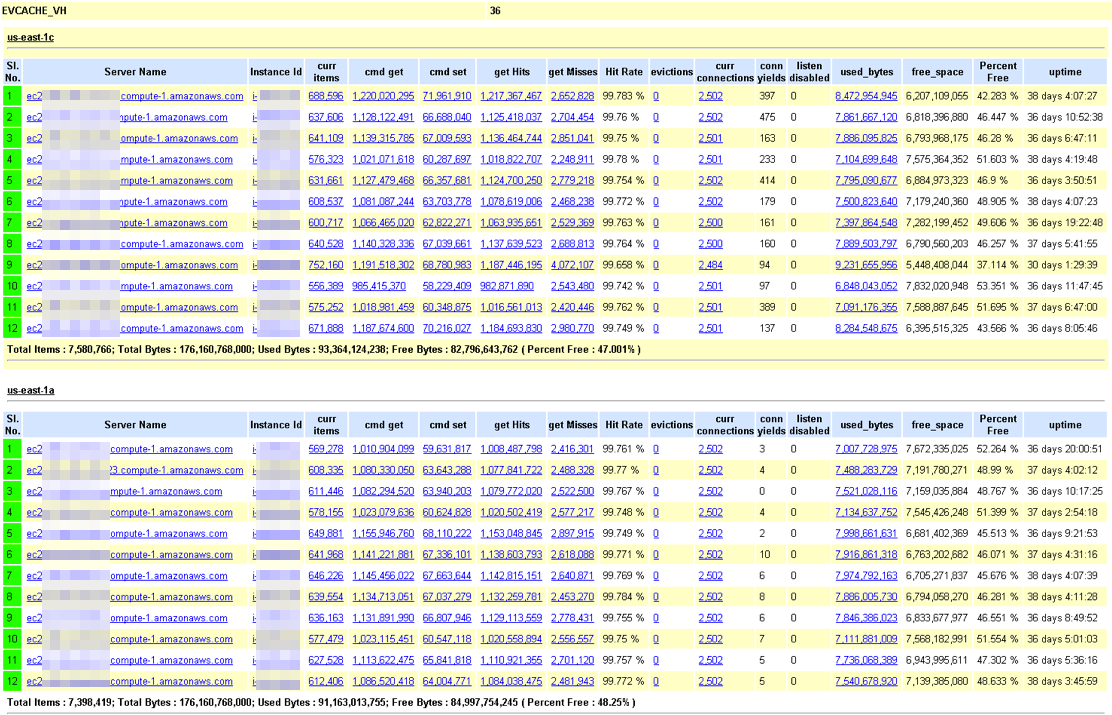
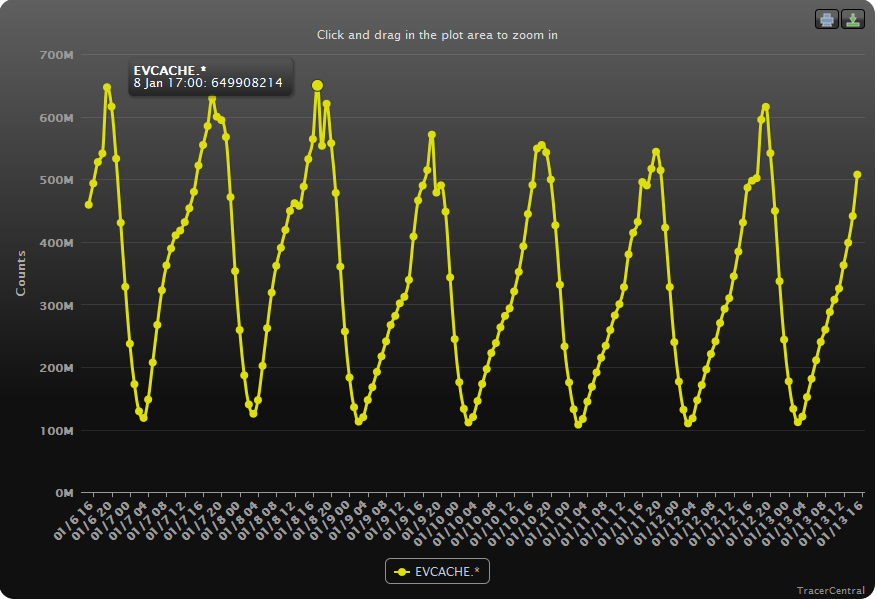
The EVCache Clusters currently serve over 200K Requests/sec at peak loads. The below chart shows number of requests to EVCache every hour.
The average latency is around 1 millisecond to 5 millisecond. The 99th percentile is around 20 millisecond.


Join Us
Like what you see and want to work on bleeding edge performance and scale?We’re hiring !
References
- TTL : Time To Live for data stored in the cache. After this time the data will expire and when requested will not be returned.
- Evicted : Data associated with a key can be evicted(removed) from the cache even though its TTL has not yet exceed. This happens when the cache is running low on memory and it needs to make some space to add the new data that we are storing. The eviction is based on LRU (Least Recently Used).
- CRUD : Create, Read, Update and Delete are the basic functions of storage.
- AWS Region : It is a Geographical region and currently in US East (virginia), US West, EU (Ireland), Asia Pacific (Singapore), Asia Pacific (Tokyo) and South America (Sao Palo).
- AWS Zone: Each availability zone runs on its own physically distinct and independent infrastructure. You can also think this as a data center.
- Naming Service : It is a service developed by Netflix and is a registery for all the instances that run Netflix Services.
- Netflix Persister Framework : A Framework developed by Netflix that helps user to persist data across various datastore like In-Memory/EVCache/Cassandra/SimpleDB/S3 by providing a simple API.
by Shashi Madappa, Senior Software Engineer, Personalization Infrastructure Team

comment 0 التعليقات:
more_vertsentiment_satisfied Emoticon