At Netflix, we are committed to bringing new features and product enhancements to customers rapidly and frequently. Consequently, dozens of engineering teams are constantly innovating on their services, resulting in a rate of change to the overall service is vast and unending. Because of our appetite for providing such improvements to our members, it is critical for us to maintain a Software Delivery pipeline that allows us to deploy changes to our production environments in an easy, seamless, and quick way, with minimal risk.
The Challenge
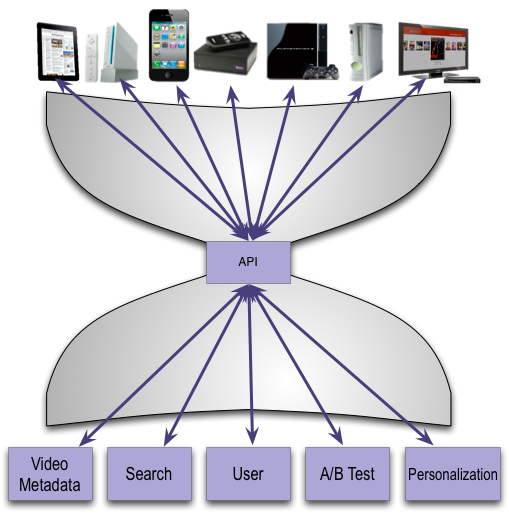
The Netflix API is responsible for distributing content that supports our features to the UIs. The API in turn, is dependent on a large number of services that are responsible for generating the data. We often use an hourglass metaphor to describe the Netflix technology stack, with the API being the slender neck.
We have already described the technology and automation that powers our global, multi-region deployments in an earlier blog post. In this post, we will delve into the earlier stages of our pipeline, focusing on our approach to generating an artifact that is ready for deployment. Automation and Insight continue to remain key themes through this part of our pipeline just as they are on the deployment side.
Delivery pipeline
The diagram below illustrates the flow of code through our Delivery pipeline. The rest of this post describes the steps denoted by the gray boxes.
Delivery pipeline
The diagram below illustrates the flow of code through our Delivery pipeline. The rest of this post describes the steps denoted by the gray boxes.

- Release - on a Weekly deployment schedule
- Prod - on a Daily deployment schedule
There are no hard and fast rules regarding which branch to use; just broad guidelines. Typically, we use the Release branch for changes that meet one of the following criteria:
- Require additional testing by people outside of the API Team
- Require dependency library updates
- Need additional "bake-time" before they can be deployed to Production
[1] Developers build and run tests in their local environment as part of their normal workflow. They make the determination as to the appropriate level of testing that will give them confidence in their change. They have the capability to wrap their changes with Feature Flags, which can be used to enable or disable code paths at runtime.
[2] Once a change is committed to the repository, it is part of the Delivery pipeline.
[3][4] Every commit triggers a Build/Test/deploy cycle on our Continuous Integration server. If the build passes a series of gates, it is deployed to one of our Pre-Production environments[5]; depending on the branch in source that the build was generated from. We maintain several environments to satisfy the varied requirements of our user base, which consists of Netflix internal Dev and Test teams as well as external partners. With this process, we ensure that every code change is available for use by our partners within roughly an hour of being committed to the repository.
[6] If the change was submitted to the Prod branch or a manual push trigger was invoked, the build is deployed to the canary cluster as well. It is worth mentioning that our unit of deployment is actually an Amazon Machine Image (ami), which is generated from a successful build. For the purposes of this post though, we'll stick to the term “build”.
Dependency Management
Testing

Continuous Integration
Contract validations
Integration Tests
User Acceptance Tests
Canary Analysis
Insight - tracking changes
Conclusion
Dependency Management
This is a good time to take a deeper look at our approach to dependency management. In the Netflix SOA implementation, services expose their interfaces to consumers through client libraries that define the contract between the two services. Those client libraries get incorporated into the consuming service, introducing build and runtime dependencies for the service. This is highly magnified in the case of the API because of its position in the middle of the hourglass, as depicted at the beginning of the post. With dozens of dependencies and hundreds of client libraries, getting a fully functional version of the API server stood up can in itself be tricky. To add to that, at any point in time, several of these libraries are being updated to support critical new functionality or bug fixes. In order to keep up with the volume and rate of change, we have a separate instance of our pipeline dedicated towards library integration. This integration pipeline builds an API server with the latest releases of all client libraries and runs a suite of functional tests against it. If that succeeds, it generates a configuration file with hardcoded library versions and commits it into SCM. Our developers and the primary build pipeline use this locked set of libraries, which allows us to insulate the team from instabilities introduced by client library changes but still keep up with library updates.
Testing
Next, we explore our test strategy in detail. This is covered in steps 1-4 in the pipeline diagram above. It is helpful to look at our testing in terms of the Software Testing Pyramid to get a sense for our multi-layered approach.
Local Development/Test iterations
Developers have the ability to run unit and functional tests against a local server to validate their changes. Tests can be run at a much more granular level than on the CI server; so as to keep the run times short and support iterative development.
Continuous Integration
Once code has been checked in, the CI servers take over. The goal is to assess the health of the branch in the SCM repository with every commit, including automated code merges between various branches as well as dependency updates. The inability to generate a deployable artifact or failed unit tests cause the build to fail and block the pipeline.
Contract validations
Our interface to our consumers is via a Java API that uses the Functional Reactive model implemented by RxJava. The API is consumed by Groovy scripts that our UI teams develop. These scripts are compiled dynamically at runtime within an API server, which is when an incompatible change to the API would be detected. Our build process includes a validation step based on API signature checks to catch such breakages earlier in the cycle. Any non-additive changes to the API as compared to the version that’s currently in Production fail the build and halt the pipeline.
Integration Tests
A build that has passed unit and contract validation tests gets deployed to the CI server where we test it for readiness to serve traffic. After the server is up and running with the latest build, we run functional tests against it. Given our position in the Netflix stack, any test against the API is by definition an integration test. Running integration tests reliably in a live, cloud-based, distributed environment poses some interesting challenges. For instance, each test request results in multiple network calls on the API server, which implies variability in response times. This makes tests susceptible to timing related failures. Further, the API is designed to degrade gracefully by providing partial or fallback responses in case of a failure or latency in a backend service. So responses are not guaranteed to be static. Several backend services provide personalized data which is dynamic in nature. Factors such as these contribute towards making tests non-deterministic, which can quickly diminish the value of our test suites.
We follow a few guiding principles and techniques to keep the non-determinism under control.
- Focus on the structure rather than the content of the responses from the API. We leave content verification to the services that are responsible for generating the data. Tests are designed with this in mind.
- Account for cold caches and connections by priming them prior to test execution.
- Design the system to provide feedback when it is returning fallback responses or otherwise running in a degraded mode so tests can leverage that information.
- Quarantine unreliable tests promptly and automate the process of associating them to tasks in our bug tracking system .
These techniques have allowed us to keep the noise in the test results down to manageable levels. A test failure in our primary suite blocks the build from getting deployed anywhere.
Another key check we perform at this stage is related to server startup time, which we track across builds. If this metric crosses a certain threshold, the pipeline is halted.
User Acceptance Tests
If a build has made it to this point, it is ready to be deployed to one or more internal environments for user-acceptance testing. Users could be UI developers implementing a new feature using the API, UI Testers performing end-to-end testing or automated UI regression tests. As far as possible, we strive to not have user-acceptance tests be a gating factor for our deployments. We do this by wrapping functionality in Feature Flags so that it is turned off in Production while testing is happening in other environments.
Canary Analysis
This is the final step in the process before the code is deployed globally. A build that has reached this step is a candidate for Production deployment from a functional standpoint. The canary process analyzes the readiness of the build from a systems perspective. It is described in detail in the post on Deploying the API.
Insight - tracking changes
Continuous Delivery is all about feedback loops. As a change makes its way through the pipeline, the automation delivers the results of each step to the concerned person(s) in real time via email and/or chat notifications. Build and Test results are also captured and made available on our Build Status Dashboard for later viewing. Everyone committing a change to the Release or Prod branch is responsible for ensuring that the branch is in a deployable state after their change. The Build Dash always displays the latest status of each branch, including a history of recent commits and test runs. Members of our Delivery Team are on a weekly rotation to ensure smooth operation of the pipelines.

Conclusion
The work we’ve done so far has been helpful in increasing our agility and our ability to scale with the growth of the business. But as Netflix grows and our systems evolve, there are newer challenges to overcome . We are experimenting in different areas like developer productivity, improved insight into code usage and optimizing the pipeline for speed. If any of these sound exciting, take a look at our open roles.

comment 0 التعليقات:
more_vertsentiment_satisfied Emoticon